Terraform Tutorial Teil 2
Falls ihr schon unseren ersten Teil zu Terraform gelesen habt, hier nun der zweite Teil, in welchem wir das Tutorial weiter führen.
Der Betrieb eines einzelnen Webervers ist ein guter Start zum üben, aber in der realen Welt ist ein einzelner Server eben auch der Single-Point of failure. Heisst, wenn dieser Server abstürzt oder durch zu viel Traffic überlastet wird, können Benutzer nicht mehr auf unsere Website zugreifen. Die Lösung besteht darin, einen Cluster von Servern zu betreiben, Server auszuschliessen und zu ersetzten, die ausgefallen sind, die Größe des Clusters je nach Verkehrsaufkommen nach oben oder unten zu skalieren und dies alles vollautomatisch.
Erstellen einer AutoScaling Gruppe
Wir können es AWS überlassen, sich darum zu kümmern, indem wir eine Auto Scaling Group (ASG) verwenden. Eine ASG kann automatisch einen Cluster von EC2-Instanzen starten, ihren Zustand überwachen, ausgefallene Knoten automatisch neu starten und die Größe des Clusters an die Anforderungen anpassen.
die LaunchConfiguration
Der erste Schritt bei der Erstellung eines ASG besteht darin, eine Startkonfiguration zu erstellen, die angibt, wie die einzelnen EC2-Instanzen konfiguriert werden sollen. Durch die frühere Bereitstellung der einzelnen EC2-Instanz wissen wir bereits genau, wie diese konfiguriert sein sollen, und Sie können fast genau die gleichen Parameter in der aws_launch_configuration-Ressource wiederverwenden:
resource "aws_launch_configuration" "tutorial" {
image_id = "ami-de486035"
instance_type = "t2.micro"
security_groups = [aws_security_group.instance.id]
user_data = <<-EOF
#!/bin/bash
echo "Hello, World" > index.html
while true ; do nc -l 80 < test.html ; done &
EOF
lifecycle {
create_before_destroy = true
}
}
Das Einzige, was hier neu ist, ist die Lifecycle-Einstellung. Terraform unterstützt mehrere Lifecycle-Einstellungen, mit denen Sie festlegen können, wie Ressourcen erstellt und beendet werden.
Die Einstellung create_before_destroy steuert die Reihenfolge, in der Ressourcen neu erstellt werden. Die Standardreihenfolge besteht darin, die alte Ressource zu löschen und dann die neue zu erstellen. Wenn Sie create_ before_destroy auf true setzen, wird diese Reihenfolge umgekehrt, indem Sie zuerst die Ersetzung erstellen und dann die alte löschen. Da jede Änderung an einer Startkonfiguration eine völlig neue Startkonfiguration mit sich bringt, benötigen Sie diese Einstellung, um sicherzustellen, dass die neue Konfiguration zuerst erstellt wird, so dass alle AutoScaling Gruppen, die diese Startkonfiguration verwenden, aktualisiert werden können, um auf die neue zu verweisen, und dann erst die alte gelöscht wird.
AutoScaling Gruppe
Nun können wir die ASG selbst mit der Ressource aws_autoscaling_group erstellen:
resource "aws_autoscaling_group" "tutorial" {
launch_configuration = aws_launch_configuration.tutorial.id
min_size = 2
max_size = 4
tag {
key = "Name"
value = "terraform-elastic2ls-asg"
propagate_at_launch = true
}
}
Diese ASG wird mit mindestens 2 und maximal 4 EC2-Instanzen laufen, die jeweils mit dem Namen terraform-elastic2ls-asg versehen sind. Die ASG verwendet eine Referenz, um den Namen der oben erstellten LaunchConfiguration anzugeben.
Damit diese ASG funktioniert, müssen wir einen weiteren Parameter angeben: availability_zones. Dieser Parameter gibt an, in welche Verfügbarkeitszonen (AZs) die EC2-Instanzen gestartet werden sollen. Jede AZ stellt ein isoliertes AWS-Rechenzentrum dar, so dass dadurch unser Dienst auch dann weiterlaufen kann, wenn eines der AZs ausfallen sollte. Wir könnten die Liste der AZs hartcodieren (z.B. auf [“us-east-2a”, “eu-central-1”]), oder wir verwenden Terraform um diese Informationen von der AWS Api abzufragen.
Die Syntax für die Verwendung einer Datenquelle ist sehr ähnlich der Syntax einer Ressource:
data "<PROVIDER>_<TYPE>" "<NAME>" {
[CONFIG ...]
}
- PROVIDER ist der Name eines Anbieters (z.B. aws)
- TYPE ist der Typ der Datenquelle, die Sie verwenden möchten (z.B. vpc)
- NAME ist eine Kennung, die Sie im gesamten Terraform-Code verwenden können, um auf diese Datenquelle zu verweisen
- CONFIG besteht aus einem oder mehreren Argumenten, die spezifisch für diese Datenquelle sind. So können Sie beispielsweise die Datenquelle aws_availability_zones verwenden, um die Liste der AZs in Ihrem AWS-Konto zu erhalten:
data.aws_availability_zones.all.names
Das können wir nun in der aws_autoscaling_group verwenden:
resource "aws_autoscaling_group" "tutorial" {
launch_configuration = aws_launch_configuration.tutorial.id
availability_zones = data.aws_availability_zones.all.names
min_size = 2
max_size = 4
tag {
key = "Name"
value = "terraform-elastic2ls-asg"
propagate_at_launch = true
}
}
Erstellen eines Load Balancers
Oben haben wir nun eine AutoScaling Gruppe, welche uns nun zwei Instanzen in zwei verschiedenen Rechenzentren zur Verfügung stellt, aber wir benötigen nun ja auch eine Möglichkeit Verkehr dort hin zurouten, eine Lastverteilung zur Verfügung zu haben und entsprechend auch zu skalieren. Hier kommt der LoadBalancer Service von AWS in Spiel.
AWS bietet drei verschiedene Arten von Lastausgleichern an:
- Application Load Balancer (ALB): bestens geeignet für HTTP- und HTTPS-Datenverkehr.
- Network Load Balancer (NLB): bestens geeignet für TCP- und UDP-Verkehr.
- Classic Load Balancer (ELB): Dies ist der “alte” Load Balancer, der sowohl dem ALB als auch dem NLB vorausgeht. Es kann HTTP, HTTPS und TCP, bietet aber weit weniger Funktionen als ALB oder NLB.
Da unsere Webserver HTTP verwenden, wäre der ALB am besten geeignet, aber es erfordert mehr Code und mehr Erklärungen. Der Einfachheit halber verwenden wir der klassichen LoadBalancer.
Du kannst einen ELB mit der Ressource aws_elb erstellen:
resource "aws_elb" "tutorial" {
name = "terraform-elastic2ls-elb"
availability_zones = data.aws_availability_zones.all.names # This adds a listener for incoming HTTP requests.
}
Dadurch wird ein ELB erstellt, der über alle AZs in der verwendeten Region verteilt wird. Die AWS LoadBalancer bestehen nicht aus einem einzigen Server, sondern aus mehreren Servern, die in separaten AZs (d.h. separaten Rechenzentren) betrieben werden. AWS skaliert automatisch die Anzahl der Load Balancer-Server nach oben und unten, basierend auf dem Traffic und managed das Failover, wenn einer dieser Server ausfällt, so dass diese hochverfügbar sind. Das ist der einer der Vorteile eines solchen gemanagten Services.
Oben gezeigtes Beispiel für den ELB tut nun noch nicht wirklich etwas. Wir müssen nun als nächstes einen oder mehrere Listener konfigurieren.
resource "aws_elb" "tutorial" {
name = "terraform-elastic2ls-elb"
availability_zones = data.aws_availability_zones.all.names # This adds a listener for incoming HTTP requests.
listener {
lb_port = 80
lb_protocol = "http"
instance_port = var.server_port
instance_protocol = "http"
}
}
Im obigen Code sagen wir dem ELB, dass er HTTP-Requests auf dem Standardport für HTTP empfangen und an den Port weiterleiten soll, der von den Instances in der AutoScaling Gruppe verwendet wird. Beachten müssen wir, dass ELBs standardmäßig keinen eingehenden oder ausgehenden Datenverkehr zulassen (genau wie EC2-Instanzen), daher müssen wir eine neue Sicherheitsgruppe hinzufügen, um eingehende Anfragen auf Port 80 und allen ausgehenden Anfragen explizit zuzulassen (letzteres soll dem ELB erlauben, Healthchecks durchzuführen).
resource "aws_security_group" "elb" {
name = "terraform-elastic2ls-sg-elb"
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
} # Inbound HTTP from anywhere
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
Wir müssen nun dem ELB mitteilen, dass er diese Sicherheitsgruppe verwenden soll, indem wir den Parameter security_groups hinzufügen:
resource "aws_elb" "tutorial" {
name = "terraform-elastic2ls-elb"
availability_zones = data.aws_availability_zones.all.names # This adds a listener for incoming HTTP requests.
security_groups = [aws_security_group.elb.id]
listener {
lb_port = 80
lb_protocol = "http"
instance_port = var.server_port
instance_protocol = "http"
}
}
Was machen wir aber wenn ein Server hinter dem LoadBalancer ausfällt? Dieser muss ja ersetzt werden und der eingehende Verkehr sollte nicht mehr auf diesen Server geroutet werden, sondern auf einen neuen Server, der den defekten ersetzt. Dazu kann man in der ELB Konfiguration einen Healthcheck definieren, der falls ein Server ausfallen sollte sofort aufhört Anfragen dorhin zu routen.
Fügen wir einen HTTP-Zustandscheck hinzu, bei dem der ELB alle 30 Sekunden eine HTTP-Anfrage an die “/”-URL jeder der EC2-Instanzen sendet und eine Instanz nur dann als gesund markiert, wenn sie mit einem 200 OK antwortet:
resource "aws_elb" "tutorial" {
name = "terraform-elastic2ls-elb"
availability_zones = data.aws_availability_zones.all.names # This adds a listener for incoming HTTP requests.
security_groups = [aws_security_group.elb.id]
health_check {
target = "HTTP:${var.server_port}/"
interval = 30
timeout = 3
healthy_threshold = 2
unhealthy_threshold = 2
}
listener {
lb_port = 80
lb_protocol = "http"
instance_port = var.server_port
instance_protocol = "http"
}
}
Woher weiß der ELB, an welche EC2-Instanzen er Anfragen senden soll? Wir müssen nun den Parameter load_balancers der Ressource aws_autoscaling_group verwenden, um die AutoScaling Gruppe anzuweisen, jede Instanz im ELB zu registrieren:
resource "aws_autoscaling_group" "tutorial" {
launch_configuration = aws_launch_configuration.tutorial.id
availability_zones = data.aws_availability_zones.all.names
min_size = 2
max_size = 4
load_balancers = [aws_elb.tutorial.name]
health_check_type = "ELB"
tag {
key = "Name"
value = "terraform-elastic2ls-asg"
propagate_at_launch = true
}
}
Wir haben auch den health_check_type für die AutoScaling Gruppe auf “ELB” konfiguriert. Der Standard Health_check_type ist “EC2”, was ein minimaler Health-Check ist, der nur dann eine Instance als unhealthy ansieht, wenn der AWS-Hypervisor sagt, dass der Server vollständig ausgefallen oder unerreichbar ist. Der “ELB”-Zustandscheck ist viel robuster, da er der AutoScaling Gruppe mitteilt, dass sie den Gesundheitscheck des ELB Services verwenden soll, um festzustellen, ob eine Instanz verfügbar ist, so das diese dann den Server austauschen kann. Auf diese Weise werden Instanzen nicht nur ersetzt, wenn sie vollständig ausgefallen sind, sondern auch, wenn sie keine mehr Anfragen bedienen, weil ihnen der Speicher ausgegangen oder ein kritischer Prozess abgestürzt ist.
Eine letzte Sache, die wir vor der Bereitstellung des Load Balancers tun sollten, ist es den DNS-Namen des ELB zur Ausgabe von terraform apply hinzuzufügen, damit man schneller testen kann. Sonst müsste man sich den Namen aus der AWS Console heraussuchen.
output "clb_dns_name" {
value = aws_elb.tutorial.dns_name
description = "The domain name of the load balancer"
}
Wenn wir terraform applyerneut ausführen, sollten wir sehen, dass die ursprüngliche einzelne EC2-Instanz entfernt wird, und an ihrer Stelle erstellt Terraform eine Startkonfiguration, ASG, ALB und eine Sicherheitsgruppe. Nach der Zusammenfassung der Änderungen geben wir “yes” ein und drücke die Eingabetaste. Wenn die Anwendung abgeschlossen ist, sollten wir die Ausgabe von clb_dns_name sehen:
Outputs:
clb_dns_name = terraform-elastic2ls-elb-1749382638.eu-central-1.elb.amazonaws.com
In der AWS Console sieht das so aus:
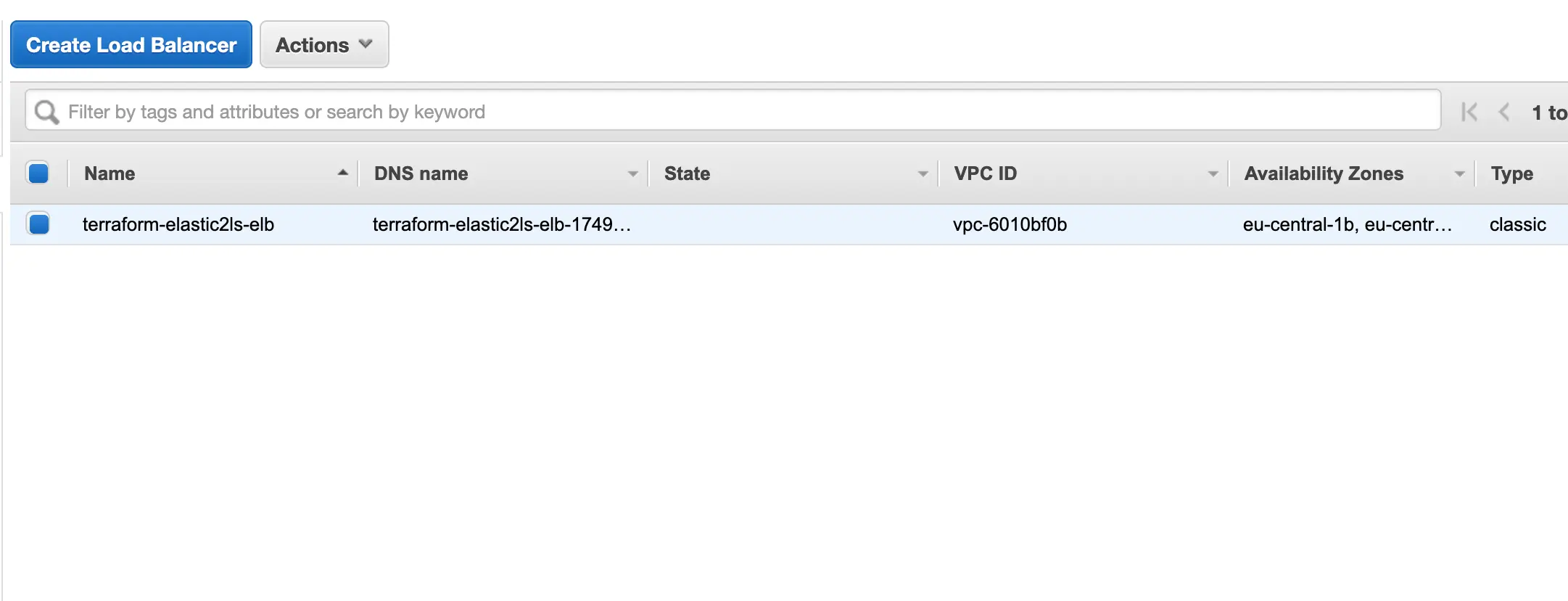
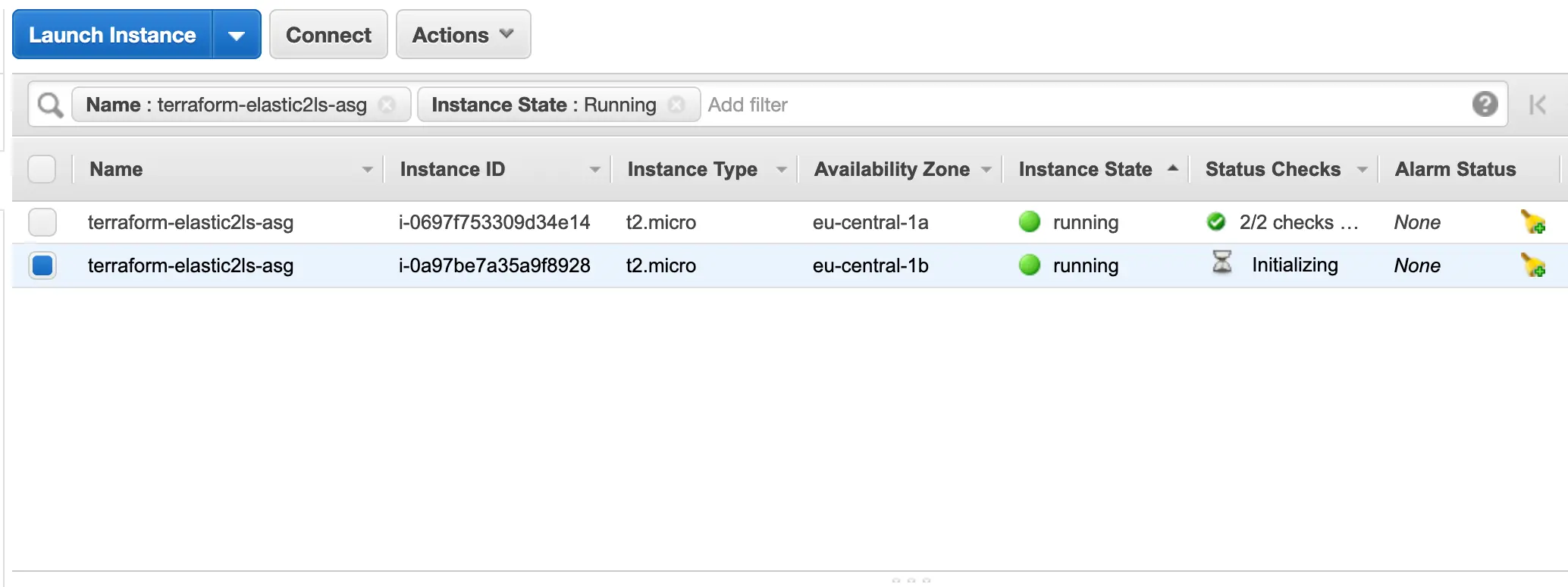
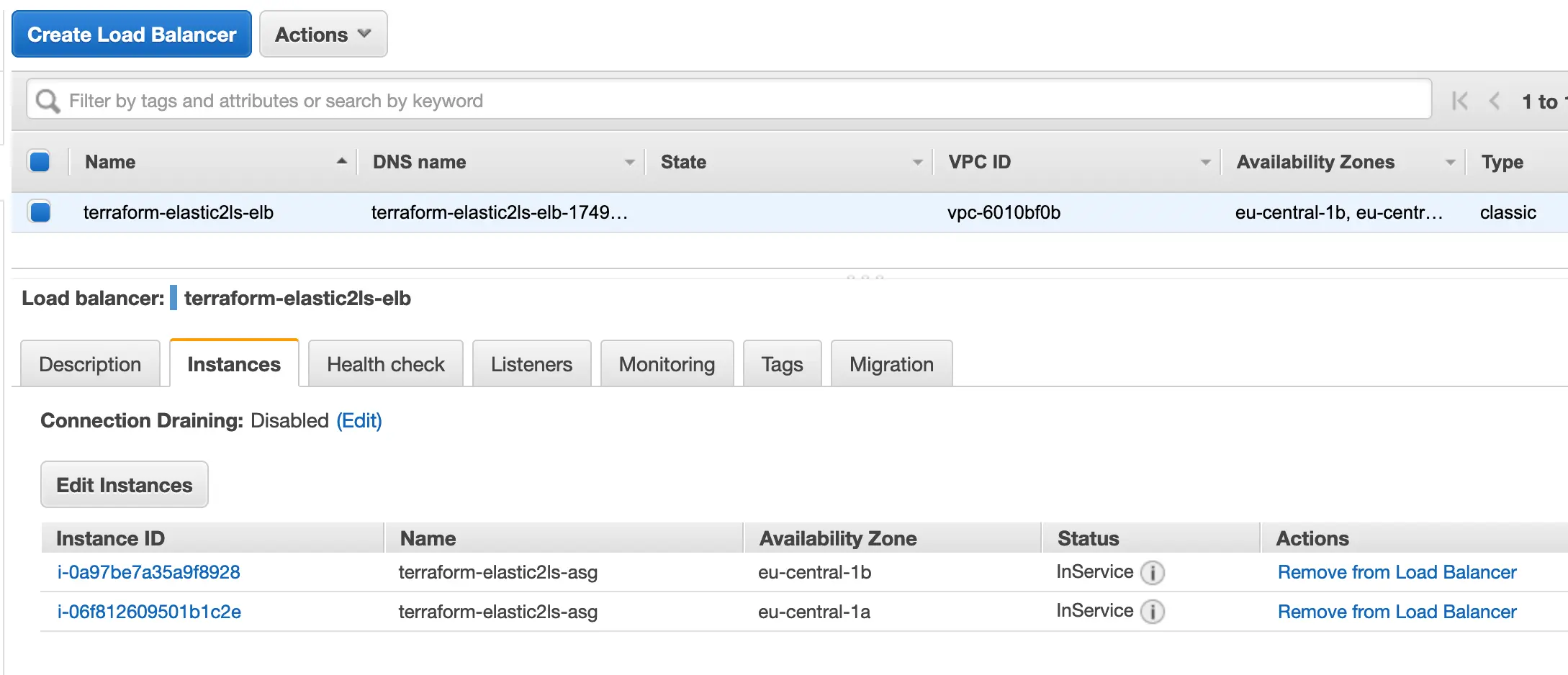
Wenn der Status der Instanzen in der Übersicht des ELBs auf InService stehen, können wir per curltesten.
$ curl terraform-elastic2ls-elb-1749382638.eu-central-1.elb.amazonaws.com
Hello, World
Geschaft! Der ELB leitet den Datenverkehr an unsere EC2-Instanzen weiter. Wir haben jetzt einen voll funktionsfähigen Cluster von Webservern!
Zur Erinnerung: Den Code für die Beispiele findet ihr unter: https://github.com/elastic2ls-com/terraform-tutorial.
An dieser Stelle können wir sehen, wie der Cluster darauf reagiert, neue Instanzen zu starten oder alte abzuschalten. Wenn wir beispielsweise auf die Registerkarte Instanzen gehen und eine der Instanzen beenden sollte alles weiter funktionieren. Testen wir die ELB-URL weiter, sollten für jede Anfrage ein “200 OK” zurückkommen, auch wenn eine Instanz beenden wurde, da der ELB automatisch erkennt, dass die Instanz ausgefallen ist, und das Routing zu dieser beendet. Noch interessanter ist, dass die ASG kurz nach dem Herunterfahren der Instanz erkennt, dass weniger als 2 Instanzen laufen, und automatisch eine neue startet, um sie zu ersetzen.
Natürlich gibt es viele andere Optionen einer AutoScaling Gruppe, die wir hier nicht behandelt haben. Für einen echten Einsatz müssen wir den EC2-Instanzen per IAM-Rollen Rechte zuweisen, einen Mechanismus einrichten, um die EC2-Instanzen ohne Ausfallzeiten zu aktualisieren, und Richtlinien zur automatischen Skalierung konfigurieren, um die Größe der AutoScaling Gruppe als Reaktion auf die Last anzupassen.
Aufräumen
Nun da wir mit dem Experimentieren mit Terraform fertig sind, ist es eine gute Idee, alle erstellten Ressourcen wieder zu entfernen, damit AWS diese nicht in Rechnung stellt. Da Terraform den Überblick darüber behält, welche Ressourcen erstellt wurden, ist die Bereinigung einfach. Alles, was du tun musst, ist den destroy-Befehl auszuführen:
$ terraform destroy
(...)
Terraform will perform the following actions:
# aws_autoscaling_group.tutorial will be destroyed
- resource "aws_autoscaling_group" "example" {
(...)
}
# aws_launch_configuration.tutorial will be destroyed
- resource "aws_launch_configuration" "example" {
(...)
}
# aws_elb.tutorial will be destroyed
- resource "aws_elb" "example" {
(...)
}
(...)
Plan: 0 to add, 0 to change, 8 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown
above. There is no undo. Only 'yes' will be accepted to confirm.
Enter a value:
Sobald wir “yes” eingeben und die Eingabetaste drücken, erstellt Terraform den Abhängigkeitsgraphen und löscht alle Ressourcen in der richtigen Reihenfolge und arbeitet dabei so viel parallel wie möglich. In etwa einer Minute alle AWS Resourcen verschwunden sein.
Zusammenfassung
Du solltest nun ein grundlegendes Verständnis für die Bedienung von Terraform haben. Die deklarative Sprache macht es einfach, genau die Infrastruktur zu beschreiben, die verwendet werden soll. Der Befehl terraform plan ermöglicht es Ihnen, Änderungen zu überprüfen und Fehler schnell zu erkennen.